Pytorch Internals: Tensors and Autograd
For all we concern, Pytorch = tensor + autograd
Wrappers on Wrappers on Wrappers
From low-level to high-level: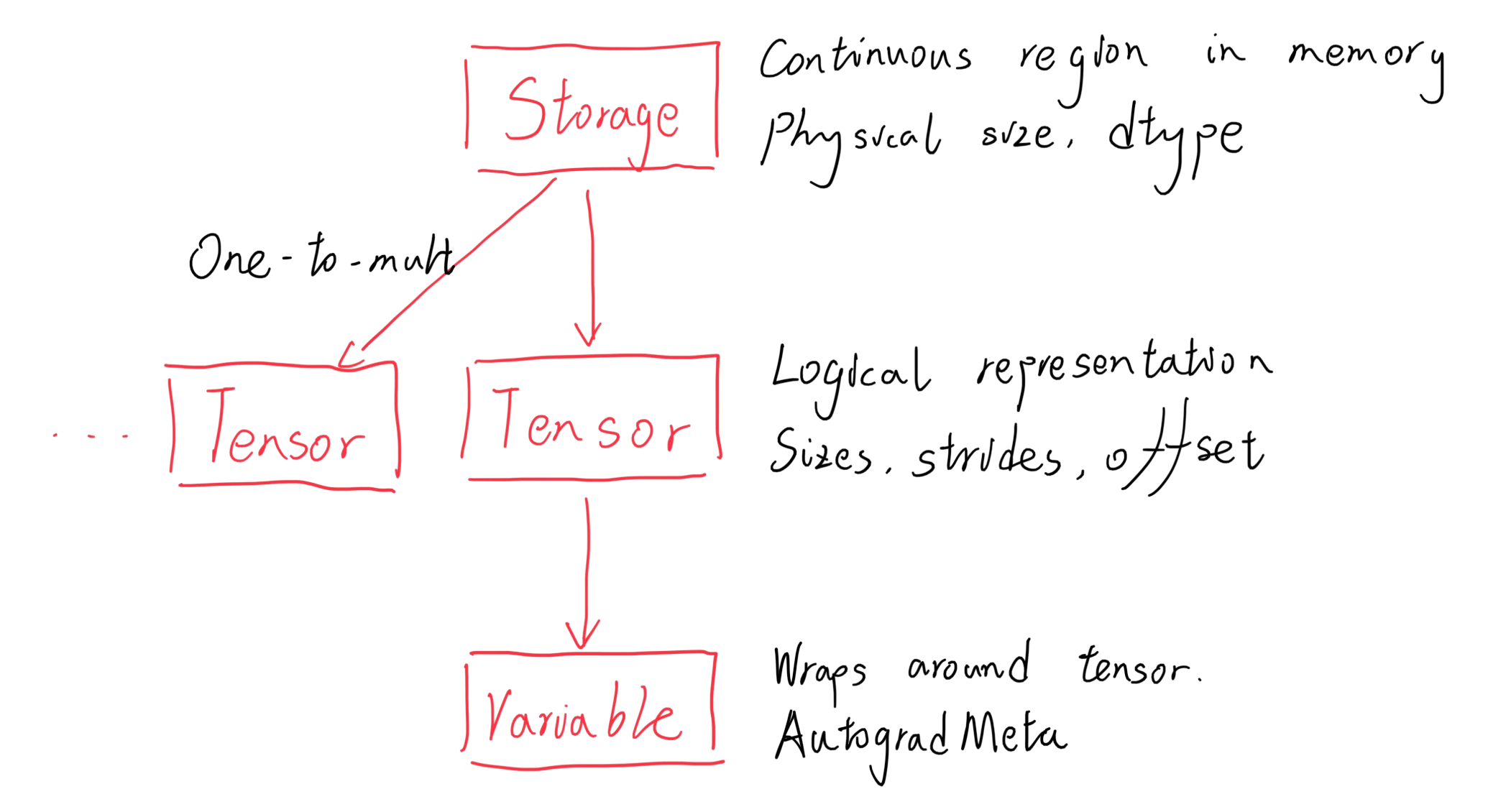
Tensor
Storage and Strides
Strides is a tuple that defines how many elements you need to traverse in memory before you reach the next row/column in a dimension in the tensor, i.e. the dimension of the tensor
When transposing or resizing a matrix, only the strides are modified, not the storage.
This leads to the concept of contiguous: a tensor is contiguous if and only if its storage is laid out from the outermost dimension to the inner most, i.e. a normal memory layout
Why does contiguousness matter? Some operations, such as view, only works for contiguous tensors.
view vs. reshape:
- When contiguous, they both return a different tensor of the same original storage
- However, when non-continuous,
viewreturns an error whilereshapecreates a contiguous copy of the input tensor’s storage and return the copied storage’s tensor
Dispatching Tensor Operations
- Dynamically (Run-time) dispatched according to device
- Dispatched according to dtype
Extending Tensors
Method 1: The Extension Point Trinity
Device (CPU, cuda, xla, hip, fpga…)
×
Layout (strided, sparse, mkldnn…)
×
dtype (float, double, int, long, bool…)
Write respective kernels for each of these combinations
Method 2: A Python Wrapper Class around Tensor
Which to use? If the tensor needs to be passed in autograd, make it a Pytorch extension
Autograd
Different Methods for Calculating the Differential
- Numerical: limit of slope
- Symbolic: similar to Wolfram, returns symbolic expression of derivative
- Automatic: uses the chain rule. For each step, the upstream derivative is passed in. Then the respective gradient-calculating function for the forward function has the mathematical formula for the single-step derivative, into which numerical values are plugged in. It outputs an accurate downstream numerical derivative
Variables’ Fields
data: tensorgrad: the numerical gradient of the variable, calculated after a backward passgrad_fn: which gradient-calculating function should the variable use, determined by the previous operation in the forward treeis_leafrequires_grad_version: used to track whether the variable’s data has changed after it was saved byctx
The Backward Tree
A backward tree is constructed according to the forward tree.
- For each variable with a
grad_fn, a gradient-calculating function node is added to the tree - For each operation needing inputs to calculate the gradient (e.g. multiplication), the operation saves the input variables and add them to the corresponding gradient-calculating function node through a context variable
ctx - For each variable with
is_leaf == Trueandrequired_grad == True,accumulate_gradis called, which takes gradients from the previous gradient-calculating function node, aggregates it, and saves it to the variable’sgradfield
References